
私たちの社会には、ブログやSNSが浸透しています。テキストマイニングを使えば、ブログやSNSのコンテンツを評価することができます。ただし、データ化するには一苦労します。今回は、テキストマイニングの方法とその可視化について整理しました。
|
目 次 |
1.はじめに
私たちは、お客様(利用者)をよりよく知るために、アンケート調査を実施します。
アンケートの設問には、大きく2種類あり、1つは選択式、もう1つは自由記述式です。
①選択式
選択式は、選択肢を用意して、それらを被験者に選んでもらう方法です。1つだけしか選べない択一回答といつでも複数回答があります。択一回答の場合は、回答数を分母に割合を単純に計算できますが、複数回答の場合には分母が異なりますので、注意しましょう。
②自由記述式
自由記述式は、言葉の通り、被験者が自由に記載する方法です。この回答方式をとる場合には、何を答えてもらうのか、被験者にわかるような質問にする必要があります。
選択式では、様々な集計方法や分析方法、集計しない(非集計)分析方法がありますが、自由記述式は、記述された内容を何となくまとめ直して終了となっている場合が多いのではないでしょうか。
そこで、テキストマイニングという方法を用います。以下には、テキストマイニングの方法やその可視化について説明します。
2.テキストマイニングとは
テキストマイニングの最も重要な要素技術は、形態素解析です。
形態素解析は、MecabとChancenがよく用いられています。Mecabはgoogleの工藤拓氏が開発に携わったことが有名で、日本語の形態素解析ではよく使われている分析器です。
このほか、英語ではTREE TAGGER、NLTK、中国語ではjieda、FNLPを利用できます。また、フランス語やドイツ語はTREE TAGGERで解析することができます。
さて、このような形態素解析の分析器はいったい何をしているのでしょうか。
形態素解析の形態素とは、言語学の用語で、平たく言えば文章を意味がわかる程度に細かく分けた一つ一つの単語のことです。単語と言えばいいのですが、日本語には単語同士が結合する時の活用形があるので、それを汲みして一つ一つを取り出します。
3.テキストマイニングの方法
テキストマイニングは、2000年代の半ばから急激な進化を遂げました。特に、形態素解析のMecabの開発は、大きなインパクトを与えました。さらに、それを後押しするように、R言語、pythonといったスクリプト式のオープンソースプログラムが開発され、学生や個人事業主、中小企業でも導入しやすくなったことが背景にあります。
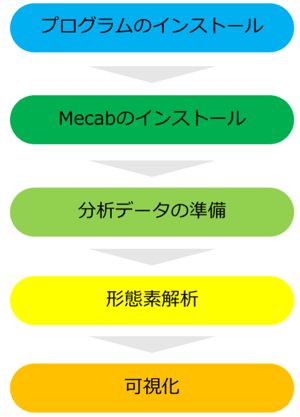
①プログラムのインストール
まずは、プログラム言語のインストールが必要です。R言語やpythonのほか、様々なプリグラム言語で利用できます。最近は、pythonのソースがたくさんネットにあげられているので、わかりやすいと思います。
②Mecabのインストール
選んだプログラム言語の環境で、Mecabをインストールします。
ここまでで、形態素解析の準備は終了です。非常に簡単です。
③分析データの準備
分析データは、テキストで準備します。1文1レコードで準備しておくと良いでしょう。ファイルの形式はtxt形式です。データ分析に慣れている技術者には当たり前かもしれませんが、txt形式のデータには、エンコードという文字形式があります。WEBで使われているのはUTF8が多く、WindowsではShift-JISが多くなっています。エンコードが一致していない場合には、形態素分析ができない場合がありますので、要注意です。
④形態素解析
後は、Mecabライブラリーを呼び出して、そこに分析データを入れれば終了です。
⑤可視化
形態素解析は、形態素に分解してくれて終わりですので、その分析結果をわかりやすく伝える必要があります。単純に、頻度をグラフ化したり、Wordcloudで可視化する方法があります。
4.テキストマイニング結果の可視化
テキストマイニングは、解体素解析が終わってしまうと、普通の分析結果と扱いはほとんど変わりません。可視化の対象とする形態素の選択です。
自由記述にどんなことが書いてあるか知りたいと思ったら、何を知りたいでしょうか。
おそらく、どのような固有名詞がよく出ているのか、ポジティブワードとネガティブワードはあるのか、といったところでしょうか。私たちのブログがどのようなワードで構成されているかを形態素解析し、その結果を可視化してみました。
分析対象は以下のとおりです。
①https://blog.marvelsupply.jp/ 内の記事より、<p>タグで囲まれた文字列をスクレイピング(全4572レコード)
②Mecabで形態素解析にて形態素に分割し、名詞、形容詞、動詞のうち頻度100~300を抽出(全62レコード)
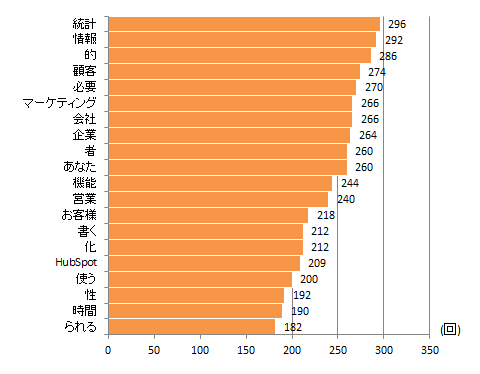
まず、一つ目は頻出形態素上位20位を棒グラフで並べてみました。統計が最も多く使っていました。その他、情報、顧客、必要、マーケティングという単語を多く使っている傾向があるようです。棒グラフだと、無駄に長いグラフになってしまうので、上位20個だけしか表示しませんでした。
 それを、wordcloudという描画方法で可視化したのが下図です。中央に頻出単語、外側にいくほど、少なくなっていきます。棒グラフだと約60程度の単語であれば、分布がなんとかわかります。グラフとwordcloud、それぞれ一長一短ありますので、両方使うと、わかりやすいです。wordcloudにはwordcloud2というのもありますので、また後日、ご紹介します。
それを、wordcloudという描画方法で可視化したのが下図です。中央に頻出単語、外側にいくほど、少なくなっていきます。棒グラフだと約60程度の単語であれば、分布がなんとかわかります。グラフとwordcloud、それぞれ一長一短ありますので、両方使うと、わかりやすいです。wordcloudにはwordcloud2というのもありますので、また後日、ご紹介します。

5.おわりに
テキストマイニングは、この10年でようやく確立されてきた分析方法です。その用途は、Google検索で予測だったり、商品のレコメンド昨日だったり、アンケートの分析だったりと非常に多岐に及んでいます。
データ分析の対象が、主に数字だった時代から、言葉もその対象に拡がったことは、これからのデータサイエンス にとって非常に大きなことです。形態素解析を組み込んだWEBシステムであれば、訪問者が検索したキーワードと自社のコンテンツが整合性を分析し、不足しているコンテンツを自動的に追加できるでしょう。
形態素解析では、「ガードレール」を「ガード」と「レール」に分割してしまったり、「ガードレール」と「防護柵」も別の品詞として判別します。このような類義語や同意語を寄せ集めるデータベースが形態素解析の基礎技術であり、最も重要です。このデータベースをどのように自社用や業界用にアレンジしていくかも非常に重要な作業になりますし、それは自社の貴重な資産になることでしょう。
今回のように、たくさんのブログが書かれていますが、そのコンテンツを評価する方法は、アクセス結果がほとんどでした。テキストマイニングを使えば、ブログそのものの評価も可能です。テキストマイニングに関心をお持ちの方は、是非ともお問い合わせくださいませ。
オススメ記事






