
Google Cloud Platform(GCP)は、誰にでもAIが身近で使いやすいものだと教えてくれます。
私たちは、よく交通関係のデータ分析をしていますが、今まで手作業でやっていたことが、GCPのautoMLvisionを使えば、簡単にAIが代わりにやってくれます。非常に簡単に利用できるので、いろいろな分野に展開していきたいと思います。
|
cover story データ分析に従事する「川崎 守さん(27)」は、まだ後輩もいないので、サポートの派遣職員さんに作業を手伝ってもらいながら、業務を担当しています。そんなときに、依頼された作業が、約6000枚の写真の分類です。アルバイトスタッフを雇用しても、微妙な判断は任せきれないため、とても工期内に終わらせることはできませんでした。しかし、画像判別分析ならできるかもしれないと、試したところ見事に工期内に終了することができました。 |
|
目 次 6.おわりに |
1.バッチ処理でやりたいこと
今回、やりたかったことは、大量のイメージデータの分類作業です。
写真の分類は、写真を集めながらコツコツとパートさんなどにやってもらう方法もありますが、私たちが扱うような写真は、経験がないパートさんでは難しいです。
というのも、右のような写真をどのような路面状況なのか判別する必要があるのです。
今回は、このような写真について、1月から3月までの3ヶ月分を収集したので、その分類します。
分類には、今回、Google Cloud Platform(GCP)からAuto ML Visionを使います。
最近では、GCPよりAmazon web Service(AWS)が多く使われているようですが、私たちがやりたいサービスはGCPの方が適合しているようです。
今回やりたかったことのまとめ
- できるだけ人手をかけずに写真を分類する
- 熟練者は忙しいので熟練者は最小限の工数にする
- GCPのAuto ML Visoinで機械学習させたモデルで2,000枚以上のイメージデータを処理する
2.GCPの準備
それでは、GCPを準備しましょう。
GCPのコンソールを開いて支払情報などを入力します。
詳細は、Google Cloud Platformの概要からどうぞ
または、GCP導入メモなどでどうぞ

ここでは、プロジェクトの作成が進みます。「新しいプロジェクト」でプロジェクト名を入力します。プロジェクトIDは自動で決まりますので、何もしなくて良いでしょう。
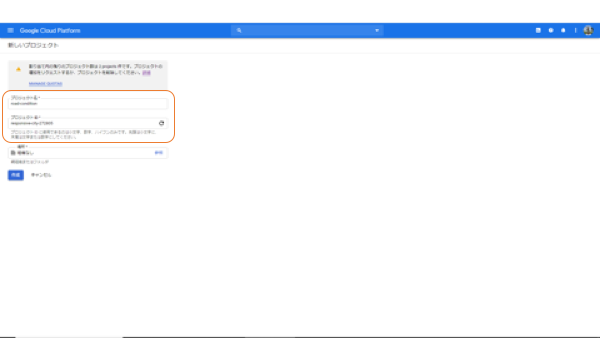
これで、プロジェクトの設定は終了です。
3.Auto ML Vision の使い方
Auto ML Visionは、Vision AIと呼ばれるプロダクトの中の1つのサービスです。Vision AIには、Auto ML Visionのほか、Vision APIとVision Product Searchがあり、これら2つのサービスは、Googleが更新している学習済みモデルを使って、顔や文字、商品などのラベリングをおこなうものです。私たちの今回の使途は、自らの写真を分類することですので、これらのサービスは使えません。
では、Auto ML Visionを使って、機械学習モデルを作成していきましょう。機械学習モデルの作成手順か下記の手順です。
①Auto ML Visionの設定
②学習用データの読み込み
③学習用データの作成
④学習モデルの作成
①Auto ML Visionの設定
左側のメニューからVisionを選びます。すると、Vsionに関わるサービスが表示されますので、ここからAuto ML Vision「使ってみる」を選びます。
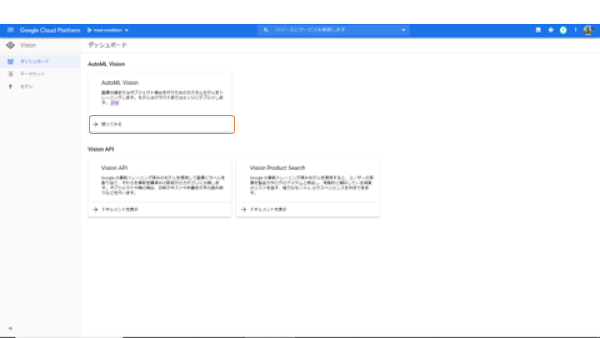
「使ってみる」を開いたのに、何もありません。
でも驚かずに、「新しいデータセット」をクリックしましょう。
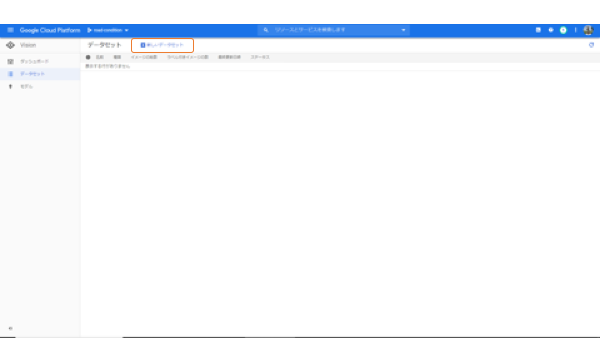
新しいデータセットの作成メニューが出てきますので、データセットの名前と検出したい分類モデルを選びます。今回は、統一ラベルを選びます。統一ラベルは、写真に対して1種類だけラベルをつけるもモデルです。このほか、複数のラベルをつけられるマルチラベル、写真の中のオブジェクトを検出するオブジェクト検出の2種類のモデルが選べます。
データセットの名前とモデルが決まったら、次に進みます。
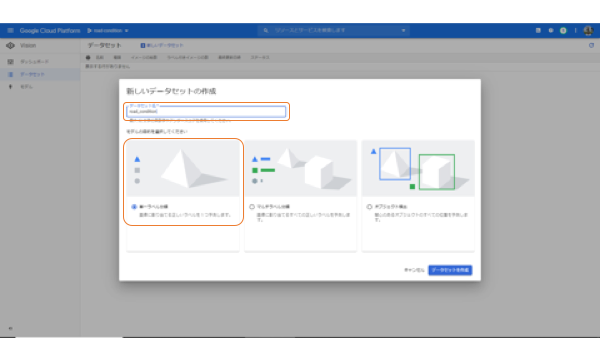
これでもうデータのインポートに進みます。データのインポートは、GCPに慣れてくるとGoogle Cloud Strageから直接インポートできますが、まずは、基本のパソコンからデータを取り込みましょう。
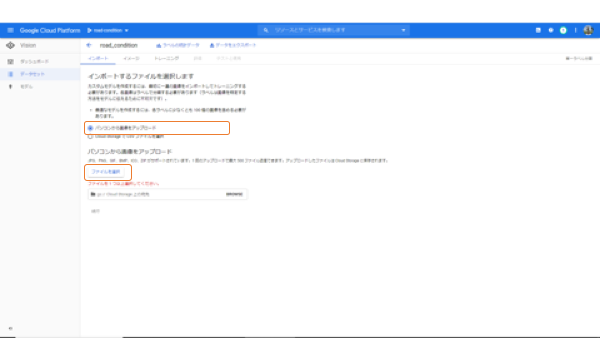
今回は、ドキュメントにおいたデータフォルダから、240枚のイメージデータを選択しました。
※JPG、PNG、GIF、BMP、ICO、ZIP がサポートされています。
1 回のアップロードで最大 500 ファイル送信できます。アップロードしたファイルは Cloud Storage に保存されます。
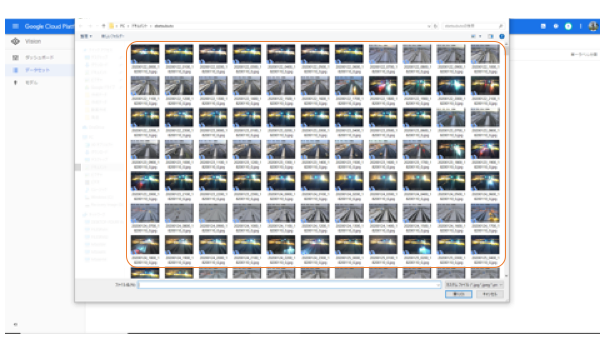
インポートするイメージデータの選択が終わったら、次は保存する場所の指定です。BROWSEをクリックして保存するCloud Strageの場所を指定します。しかし、初めてGCPを使うと、何も表示されませんので、右上の「+」をクリックします。
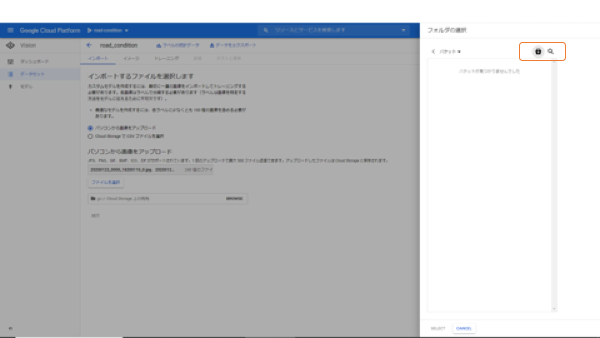
ここからは少し慎重に進みましょう。慌ててやったり、ノリで進むと間違います。
バケットに名前をつけます。バケットという言葉に馴染みがなければ、フォルダと思っておいても大きな問題はないでしょう。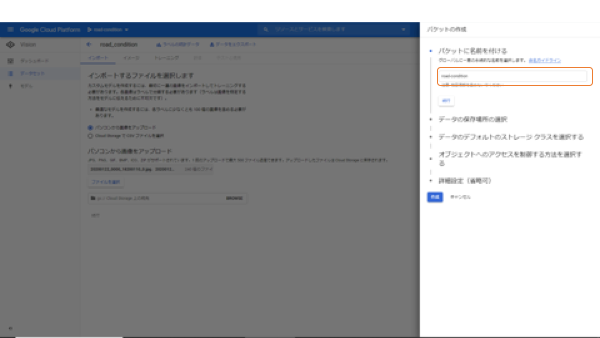
続いて、バケットのリージョンを指定します。ここをお読みのほとんどの方は日本人の方でしょうから、アジアで即決、とはいきません。
このAuto ML Visionの機械学習はUS-Centralでしか学習できません。そして、学習させるデータが保存されているバケットのリージョンもそのリージョンに合わせる必要があります。
ですから、間違いなく「US-Central」を指定します。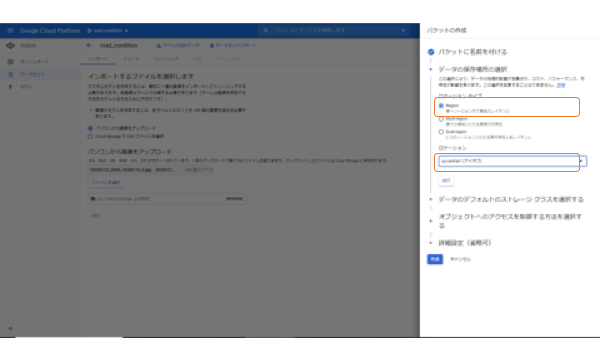
続いて、Strageのクラスを指定します。これもStandard「一択」です。GCPの仕様としてStandard出なくてはいけません。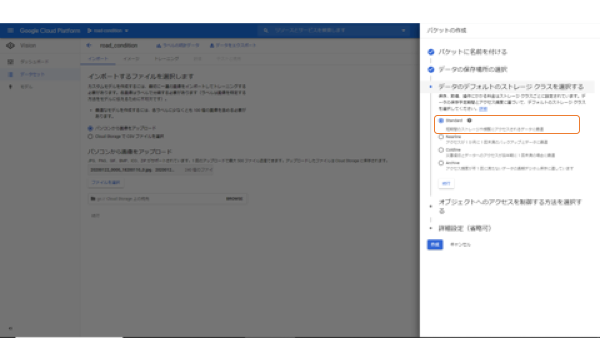
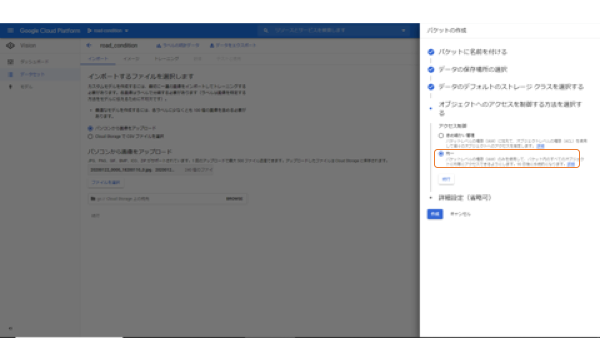
バケット最後の設定は、アクセス権限ですが、これはどちらでも大丈夫ですが、私は均一を選択しています。これでバケットの設定は終了です。
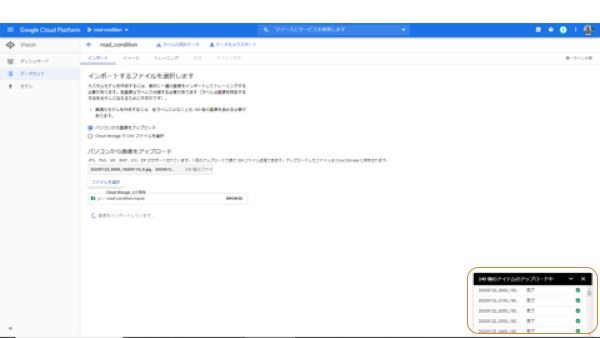
では、データをインポートしましょう。右下にインジケータが表示されますが、これはアップロードのインジケータです。アップロードが終わってから、インポート終了まで少し時間がかかります。
このアップロードが終わってからの間、GCP内ではインポートした画像リストに学習データ、検証データ、テストデータのフラグやファイルパスが記述されたcsvファイルを作成ています。
なお、この段階で、バケットの設定が間違っているとエラーで止まってしまいますので、止まってしまったらバケットの設定をやり直しましょう。うまくインポートできたら、「イメージ」タブに下のようにイメージデータのサムネイルが表示されます。
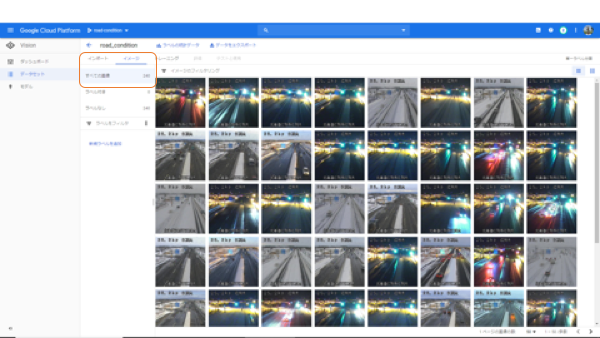
このデータをもとに、ラベルをつけていきましょう。コツコツとファイルを選択してラベルを付ける作業を繰り返します。
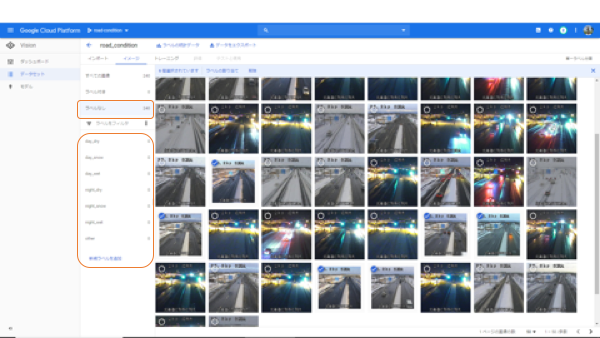
ここで、1度トレーニングのタブを開いてみましょう。このアラート(●)がすべてなくなるまで、イメージデータにラベルをつけていく必要があります。
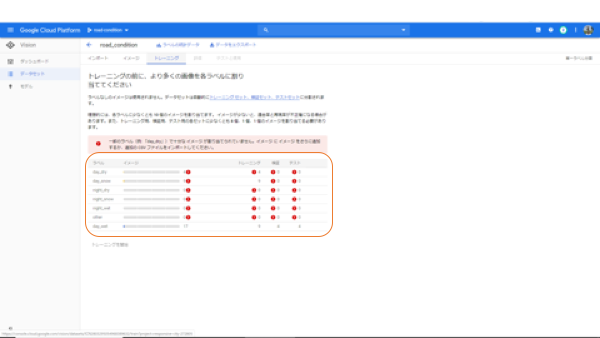
すべてのアラートがなくなると、下のようになります。今回はいくつか不要のラベルがあったので、削除しました。「トレーニング開始」をクリックすると、トレーニングを開始します。トレーニングには2~4時間くらいかかりますので、トレーニングを始める前に、もう一度ラベルに間違いがないか確認しましょう。
GCPの料金はこの段階で初めて発生します。これくらいのラベル数で5000円前後です。
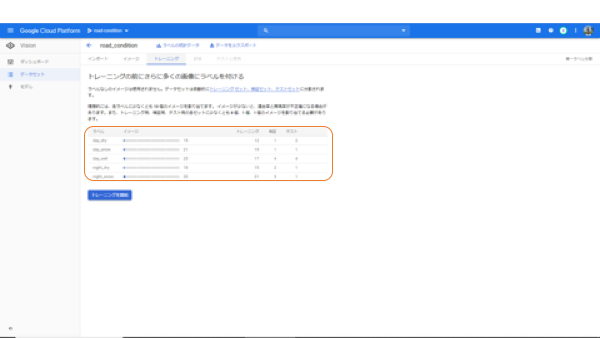
トレーニング中。
トレーニング中、この画面を眺めていてもつまらないので、別の作業をします。分類したいイメージのアップロードです。パラレルタスクになるので、トレーニングの終了まで進みます。
トレーニングが終わったら、できたモデルのチェックをしましょう。
4.バッチ処理で写真分類
今回は、分類結果を出力したいだけなので、Google コマンドラインツールからcurlでAPIを動かします。もちろん、WEBアプリケーションとして使用する場合には、FIREBASEやApp Engineなどからも利用できます。
はじめに、Google Cloud SDKをインストールして、Google コマンドラインツールを使用する方法を確認しておいてください。詳しくは、Google Cloud SDKのインストールをお読みください。(https://cloud.google.com/sdk/install?hl=ja)
①キーファイルをダウンロード
キーファイルは、Google Cloud コンソールの「IAMと管理」-「サービスアカウント」から作成してください。
※ダウンロードは、デフォルトでは、ダウンロードフォルダに保存されます。外部に漏洩しないように十分に気をつけましょう。
ダウンロードしたキーファイルを $ set でセットしておきます
$ set GOOGLE_APPLICATION_CREDENTIALS=C:\******.json(キーファイルのパス)
次に、アクセストークンを取得します。Macなどでは、curlで一緒に呼び出せますが、Windowsでは対応していませんので、先に取得します。
$ gcloud auth application-default print-access-token
ここで、ようやくAPIを呼び出します。
前で取得したアクセストークン、プロジェクトID、モデルIDが必要になりますので、GCPコンソールからコピペしておきましょう。
$ curl -X POST -H "Content-Type: application/json" -H "Authorization: Bearer *************(取得したaccess-tokenを)" https://automl.googleapis.com/v1beta1/projects/********(プロジェクトのID)/locations/us-central1/models/*************(モデルID):predict -d @c:\****.json(json形式のデータでinputデータやアウトプットのディレクトリを指定します)
特に、問題がなければ、下記のように、jsonで指定した内容が返ってきます。キーファイルも、アクセストークンも期限がありますので、都度、取得してください。キーファイルを設定し忘れたり、他の作業に没頭していてアクセストークンの期限が切れてしまったりする可能性があります。
{
"inputConfig": {
"gcsSource": {
"inputUris": [ "input-storage-path" ]
}
},
"outputConfig": {
"gcsDestination": {
"outputUriPrefix": "output-storage-bucket"
}
},
"params": {
"score_threshold": "0.0"
}
}
※メモ
1つだけまだはっきりと解決できていない問題がありました。分類するイメージファイルのパスを記述したcsvをGoogle Cloud Strageに置きますが、このcsvがなかなか認識されませんでした。ファイル形式がUTF-8のはずですが、認識されるファイルとされないファイルがありました。
あとは、分類が終わるのを待つだけですが、今回は約30分ほどの処理時間でした。
5.まとめ
総じていえば、Auto ML Visionによる写真の分類は、非常に使いやすいサービスでした。
良かったところ、悪かったところをいくつか挙げておきます。
◆良かったところ
・GCPのアカウント設定からサービス利用までがわかりやすい
・学習データを作成するためのGUIが非常に使いやすい
・英語が多いが動画の学習コンテンツが多い
・モデルが非常に素直で、学習データを作った人間が迷ったところもきっちり再現してくれます。
◆悪かったところ
・少しタイムラグがあるので、操作が重複する場合があります
・デプロイしたまま忘れていると使っていなくても課金されます
・ファイルを仕様どおりに作ってもエラーがでることがあります
同じようなファイルでエラーが出ない場合もあります(原因不明のまま解決済)
以上、GCPのAuto ML Visionの使い方について詳述しました。
これからイメージデータの分類してみようかなという方も簡単に使えると思います。
イメージデータが溢れているので、いろいろな応用ができると思います。
オススメ記事
AI・機械学習の導入・運用支援は、マーベルサプライまで・中小企業から上場企業まで、規模に関わらず対応可能 ・小売業、製造業、IT企業など、幅広い業種への導入実績 ・トラブル、簡単なご質問にも、素早く丁寧に対応
|







